
Canonical simplification of networking and the Internet
Thesis
Was accepted 09 Feb 2005 in partial fulfillment for MS(CS)
advisor Jason Nieh
pdf
(pages 115-118 temporarily suppressed for intellectual property reasons)
Problem
Current principles of networking are bottom-up:
addresses must be first assigned to nodes,
then routes compute and applications configured
in terms of the assigned addresses.
This incurs
address management,
route setup and maintenance,
and application configuration
overheads.
Similar problems of addressing and routing data elements
in host systems and applications
are handled quite differently
in modern computing:
numeric addressing is localized to
individual primary or secondary storage mechanisms,
while addressing at application program or user level
is performed by variable, table or file names.
Host operating system, database and filesystem software
manage
both the name and storage address spaces
and ensure
fast, efficient transport
on scales inconceivable
for armies of mainframe operators and pre-assembler programmers.
Concept
Eliminating
the end to end numeric address space of IP
and its limitations, management and coordination
requires
direct translation from the network namespace,
currently defined by the DNS,
into
end to end routing at
the Layer 2 forwarding plane.
This does not imply losing
any of the routing and redirection capabilities
of the current Internet,
but merely dropping
the end point identifier role of IP addresses in
application layer sockets
and the illusion of
a single end to end network address space.
A canonical (i.e. fundamental theoretical) form of networking, guaranteeing
- coordination-free addressing and routing
(without nonlocal computation),
in particular, meaning
no IANA
and
no US-centrism or "root kings",
and on any scale
including and especially
more simply and cheaply well beyond IPv6;
- subsecond additions, deletions or relocations
of entire subnetworks,
and
instant response to all name/address changes;
- elegant, scalable and efficient support for
any number of equally uncoordinated
application-specific internets;
- bottom-up evolutionary constructibilty,
i.e. by any number of
independent initial deployments as separate trees,
which may link up opportunistically to form
larger trees,
or layer over one another as
application-specific trees;
- complete generality (protocol suite-agnostic):
equally and efficiently deployable over both
existing Layer 3 (IP) infrastructure
or natively over Layer 2 infrastructures;
and
- inherent non promiscuous -- authenticate before connect
security,
in a robust, scalable and intuitive-to-manage form
very like a Unix filesystem.
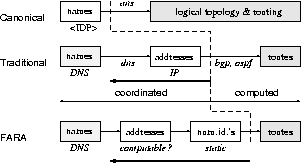
The present protocol serves as
a generic inter-domain protocol (IDP),
relegating IP to the role of
an intranet protocol suite!
It essentially eliminates
the coordinated Layer 3 address space,
as shown on the right,
where the thick arrows indicate
the simplification achieved.
The figure also compares
FARA,
which calls for
two sets of coordinated number spaces
instead of one,
echoing the (failed) Nimrod idea of the 1990s
(RFC 1992)
in postulating dynamic mappings from
a second set of mobile ids,
and with absolutely no assurance of
a fundamental improvement in terms of
either addressing or routing,
the two basic functions expected of a networking architecture.
The idea of using names directly as addresses
has been also promoted in
Stanford's TRIAD project,
but that scheme is one of
relative addressing by names,
i.e. like the historical UUCP with no form of absolute addresses,
and once again,
no fundamental improvements are offered
with respect to addressing or routing.
A computationless and coordination-free
absolute network address space
is the fundamental contribution.
The first four key properties listed are obtained by exploiting
three fundamental properties of
a tree graph structure:
- it defines a natural address space for its nodes,
i.e. provides addressing without additional coordination;
- it is inherently a spanning tree linking all of its nodes,
i.e. provides routing without route discovery or manual configuration;
and
- it provides these properties
for an unlimited number of nodes, even if
each node can only handle a small number of links.
(To compare, only the second property is exploited in
NIRA.)
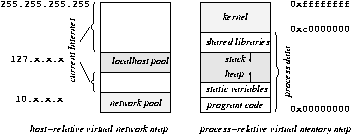
 The generality and full Layer 3 compatibility,
without Layer 3 end to end addressing dependence
(see RFC 2775 Internet Transparency)
is illustrated by the second figure,
which shows how
a client host a in private network A
can be simultaneously connected to
an external host at address 216.239.39.104 (a Google address)
and
a second host within A
given exactly the same numeric address with A.
The trick is to use
a virtual IP address for the external host
at A's gateway gA,
thus mapping external hosts
to virtual internal addresses.
This is
an exact inverse of NAT,
which maps
internal hosts to the external network address space.
This was in fact inspired by
the virtual memory addressing in (most versions of) Unix,
in which
each process gets its own virtual address space
wherein external resources can be differently mapped,
as shown by the next figure below right.
Correspondingly,
NAT can be compared to bank switched addressing of memory,
used in embedded system design
and has the spirit of mainframe architecture and programming.
The generality and full Layer 3 compatibility,
without Layer 3 end to end addressing dependence
(see RFC 2775 Internet Transparency)
is illustrated by the second figure,
which shows how
a client host a in private network A
can be simultaneously connected to
an external host at address 216.239.39.104 (a Google address)
and
a second host within A
given exactly the same numeric address with A.
The trick is to use
a virtual IP address for the external host
at A's gateway gA,
thus mapping external hosts
to virtual internal addresses.
This is
an exact inverse of NAT,
which maps
internal hosts to the external network address space.
This was in fact inspired by
the virtual memory addressing in (most versions of) Unix,
in which
each process gets its own virtual address space
wherein external resources can be differently mapped,
as shown by the next figure below right.
Correspondingly,
NAT can be compared to bank switched addressing of memory,
used in embedded system design
and has the spirit of mainframe architecture and programming.
The immediate catch is
how to get a global tree structure going without coordination.
This is partly addressed by
two further properties of the tree graph structure:
- it is a natural form for arranging named entities,
as in file systems and postal addressing;
- it is the oldest and the most common form of organizational structure,
from wolves and primates to mankind,
and
defines the administrative and security boundaries
in virtually
every government, business and academic institution;
and partly by the facts that
there is already an inherent hierarchy of service
(a provider wouldn't subscribe to
one of its own subscribers or a descendent thereof
for the same service),
and that
each provider-subscriber relation is necessarily embodied by
a physical and logical network link
which needs to be only pair-wise link-local coordination.
 Other issues that have been addressed include:
Other issues that have been addressed include:
- how to avoid the triangular routing given by the tree-walks;
- who gets to be the root king, or conversely,
can we not do without such kings (or bearers of root traffic loads);
- how this will handle dynamic change, e.g. mobility, provider changes;
- how can it compete with DNS and IP in efficiency and performance
with respect to either connection setup or datagrams
(measured first-connect times are in fact
almost as good as plain IP,
i.e. without the currently needed DNS lookup);
and
- whether the discovery-independent routing can really substitute for BGP,
i.e. whether we would still run into route table explosion
and the related multihoming issue.
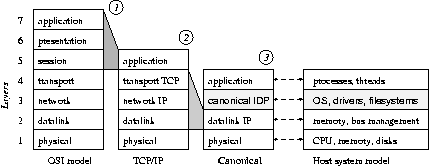
The remaining figure explains
how this approach fits in the evolution of networking.
While TCP/IP effectively combines
Layers 5, 6 and 7 into a single application layer
over TCP/UDP transport,
the present approach uses
Layers 2, 3 and 4 for its tree links
(treating TCP (or SCTP) roughly as SSCOP in ATM).
The principal layers of software in a modern (Unix, Windows) host
are also shown for analogy.
